Approach
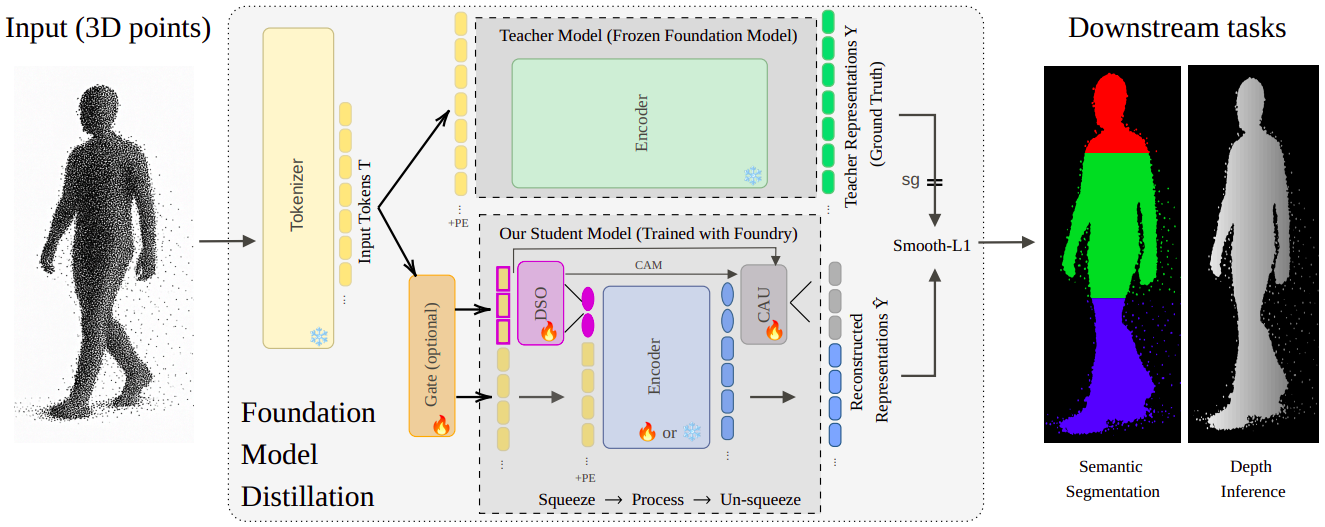
Our distillation strategy follows a compress-and-reconstruct pipeline. The student model uses a Dynamic Supertoken Optimization (DSO) module to compress the input tokens into a small set of learnable SuperTokens. After processing by a lightweight encoder, a Cross-Attention Upsampling (CAU) module reconstructs an approximation of the teacher's latent space. The entire student is trained to minimize the reconstruction error, forcing the SuperTokens to become a powerful, compact basis for the teacher's representations.

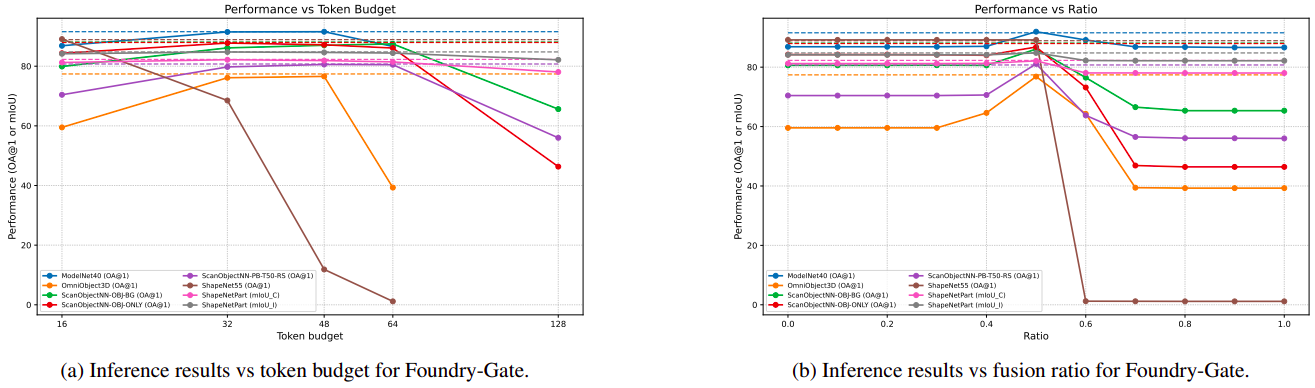
For a small s, we see Foundry needs less computation to perform a forward pass compared to a regular Transformer. Foundry-Gate takes another parameter r which can be fixed by the user or dynamic by the gate itself. In the worst case r=0 (and s=0 because no token selected for merging), we match Transformer complexity and best, complexity of Foundry.